FastAPIで完璧なブログを構築:投稿の全文検索
Wenhao Wang
Dev Intern · Leapcell

前回の記事で、ブログ投稿に画像アップロード機能を追加しました。
時間が経つにつれて、ブログにはかなりの数の記事が蓄積されていることでしょう。新しい問題が徐々に現れます。読者は目的の記事を素早く見つけるにはどうすればよいでしょうか?
もちろん、答えは検索です。
この記事では、ブログに全文検索機能を追加します。
SQLのLIKE '%keyword%'クエリを使用して検索を実装することはできないかと思うかもしれません。
簡単なシナリオでは、確かに可能です。しかし、LIKEクエリは大量のテキストを扱う場合にパフォーマンスが悪く、あいまい検索(例:「creation」を検索しても「create」に一致しない)を処理できません。
そのため、より効率的なソリューションを採用します。PostgreSQLの組み込み全文検索(FTS)機能を利用します。これは高速なだけでなく、ステミングや関連性によるランキングなどの機能もサポートしており、LIKEよりもはるかに優れた検索機能を提供します。
ステップ1:データベース検索インフラストラクチャ
PostgreSQLのFTS機能を使用するには、まずpostテーブルにいくつかの変更を加える必要があります。中心的な考え方は、高速で検索可能な最適化されたテキストデータを格納するための専用列を作成することです。
コアコンセプト:「tsvector」
postテーブルにtsvector型の新しい列を追加します。これは、記事のタイトルとコンテンツを個々の単語(レキシム)に分解し、正規化します(例:「running」と「ran」を「run」に処理)。これは、後続のクエリのためです。
テーブル構造の変更
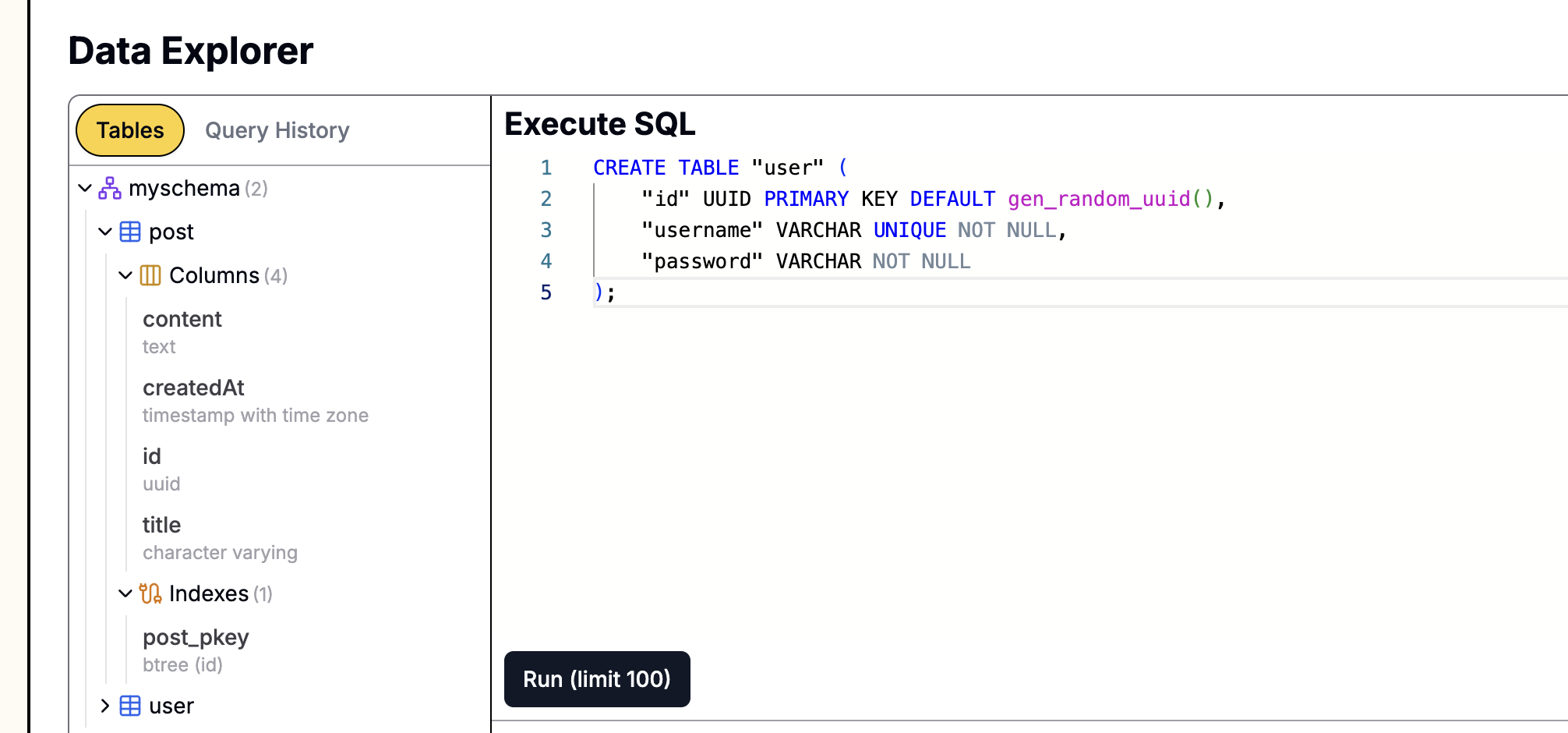
PostgreSQLデータベースで次のSQLステートメントを実行して、postテーブルにsearch_vector列を追加します。
ALTER TABLE "post" ADD COLUMN "search_vector" tsvector;
データベースがLeapcellで作成された場合、

グラフィカルインターフェイスを使用してSQLステートメントを簡単に実行できます。ウェブサイトのデータベース管理ページに移動し、上記のステートメントをSQLインターフェイスに貼り付けて実行するだけです。
既存の投稿の検索ベクターの更新
検索ペア(search_vector)が更新されると、投稿が検索可能になります。
ブログにすでにいくつかの記事があるので、次のSQLステートメントを実行するだけで、それらのsearch_vectorデータを生成できます。
UPDATE "post" SET search_vector = setweight(to_tsvector('english', coalesce(title, '')), 'A') || setweight(to_tsvector('english', coalesce(content, '')), 'B');
トリガーによる自動更新
投稿が作成または更新されるたびにsearch_vector列を手動で更新したい人はいません。最善の方法は、データベースにこの作業を自動的に実行させることです。これはトリガーを作成することで達成できます。
まず、上記のクエリと同様に、投稿のsearch_vectorデータを生成する関数を作成します。
CREATE OR REPLACE FUNCTION update_post_search_vector() RETURNS TRIGGER AS $$ BEGIN NEW.search_vector := setweight(to_tsvector('english', coalesce(NEW.title, '')), 'A') || setweight(to_tsvector('english', coalesce(NEW.content, '')), 'B'); RETURN NEW; END; $$ LANGUAGE plpgsql;
setweight関数を使用すると、異なるフィールドからのテキストに異なる重みを割り当てることができます。ここでは、タイトルの重み('A')をコンテンツ('B')よりも高く設定しました。これは、検索結果で、タイトルにキーワードが含まれる記事のランキングが高くなることを意味します。
次に、新しい投稿が挿入(INSERT)または更新(UPDATE)されるたびに、先ほど作成した関数を自動的に呼び出すトリガーを作成します。
CREATE TRIGGER post_search_vector_update BEFORE INSERT OR UPDATE ON "post" FOR EACH ROW EXECUTE FUNCTION update_post_search_vector();
検索インデックスの作成
最後に、検索パフォーマンスを確保するためにsearch_vector列にGIN(Generalized Inverted Index)を作成する必要があります。
CREATE INDEX post_search_vector_idx ON "post" USING gin(search_vector);
これで、データベースは検索準備が整いました。すべての記事の効率的な検索インデックスを自動的に維持します。
ステップ2:FastAPIでの検索ロジックの構築
データベースレイヤーを準備したので、検索リクエストを処理するバックエンドコードを記述するために、FastAPIプロジェクトに戻りましょう。
検索ルートの作成
検索関連のロジックは、routers/posts.pyファイルに直接追加します。SQLModelはSQLAlchemyをベースにしているため、SQLAlchemyのtext()関数を使用して生のSQLクエリを実行できます。
routers/posts.pyを開き、次の変更を行います。
# routers/posts.py import uuid from fastapi import APIRouter, Request, Depends, Form, Query from fastapi.responses import HTMLResponse, RedirectResponse from fastapi.templating import Jinja2Templates from sqlmodel import Session, select from sqlalchemy import text # text関数をインポート from database import get_session from models import Post from auth_dependencies import get_user_from_session, login_required import comments_service import markdown2 router = APIRouter() templates = Jinja2Templates(directory="templates") # ... 他のルート ... @router.get("/posts/search", response_class=HTMLResponse) def search_posts( request: Request, q: str = Query(None), # クエリパラメータから検索用語を取得 session: Session = Depends(get_session), user: dict | None = Depends(get_user_from_session) ): posts = [] if q: # ユーザー入力をto_tsqueryで理解できる形式に変換 # (例:「fastapi blog」を「fastapi & blog」に) search_query = " & ".join(q.strip().split()) # 全文検索に生のSQLを使用 statement = text(""" SELECT id, title, content, "createdAt" FROM post WHERE search_vector @@ to_tsquery('english', :query) ORDER BY ts_rank(search_vector, to_tsquery('english', :query)) DESC """) results = session.exec(statement, {"query": search_query}).mappings().all() posts = list(results) return templates.TemplateResponse( "search-results.html", { "request": request, "posts": posts, "query": q, "user": user, "title": f"Search Results for '{q}'" } ) # このルートが/posts/searchの後にあることを確認して、ルートの競合を避ける @router.get("/posts/{post_id}", response_class=HTMLResponse) def get_post_by_id( # ... 関数内容はそのまま ... # ...
コード解説:
- ファイルの先頭に
from sqlalchemy import textを追加します。 - 新しい
/posts/searchルートが追加されます。/posts/{post_id}ルートと競合しないように、この新しいルートをget_post_by_idルートの前に配置してください。 q: str = Query(None):FastAPIはqの値をURLのクエリ文字列(例:/posts/search?q=keyword)から取得します。to_tsquery('english', :query):この関数は、ユーザーが提供した検索文字列を、tsvector列と照合できる特別なクエリタイプに変換します。複数の単語を&で結合して、すべての単語が一致する必要があることを示します。@@演算子:これは全文検索の「一致」演算子です。WHERE search_vector @@ ...という行が検索操作の核心です。ts_rank(...):この関数は、クエリ用語がブログ記事とどれだけうまく一致するかを基にした「関連性ランキング」を計算します。最も関連性の高い記事が最初に表示されるように、このランクで降順にソートします。session.exec(statement, {"query": search_query}).mappings().all():生のSQLクエリを実行し、.mappings().all()を使用して結果を辞書のリストに変換し、テンプレートで簡単に使用できるようにします。
ステップ3:検索機能をフロントエンドに統合
バックエンドAPIが準備できました。次に、ユーザーインターフェイスに検索ボックスと検索結果ページを追加しましょう。
検索ボックスの追加
templates/_header.htmlファイルを開き、ナビゲーションバーに検索フォームを追加します。
<header> <h1><a href="/">My Blog</a></h1> <nav> <form action="/posts/search" method="GET" class="search-form"> <input type="search" name="q" placeholder="Search posts..." required> <button type="submit">Search</button> </form> {% if user %} <span class="welcome-msg">Welcome, {{ user.username }}</span> <a href="/posts/new" class="new-post-btn">New Post</a> <a href="/auth/logout" class="nav-link">Logout</a> {% else %} <a href="/users/register" class="nav-link">Register</a> <a href="/auth/login" class="nav-link">Login</a> {% endif %} </nav> </header>
検索結果ページの作成
templatesディレクトリにsearch-results.htmlという名前の新しいファイルを作成します。このページは検索結果を表示するために使用されます。
{% include "_header.html" %} <div class="search-results-container"> <h2>Search Results for: "{{ query }}"</h2> {% if posts %} <div class="post-list"> {% for post in posts %} <article class="post-item"> <h2><a href="/posts/{{ post.id }}">{{ post.title }}</a></h2> <p>{{ post.content[:150] }}...</p> <small>{{ post.createdAt.strftime('%Y-%m-%d') }}</small> </article> {% endfor %} </div> {% else %} <p>No posts found matching your search. Please try different keywords.</p> {% endif %} </div> {% include "_footer.html" %}
実行とテスト
アプリケーションを再起動します。
uvicorn main:app --reload
ブラウザを開き、ブログのホームページに移動します。
「testing」というキーワードを含む新しい記事を書いてみましょう。
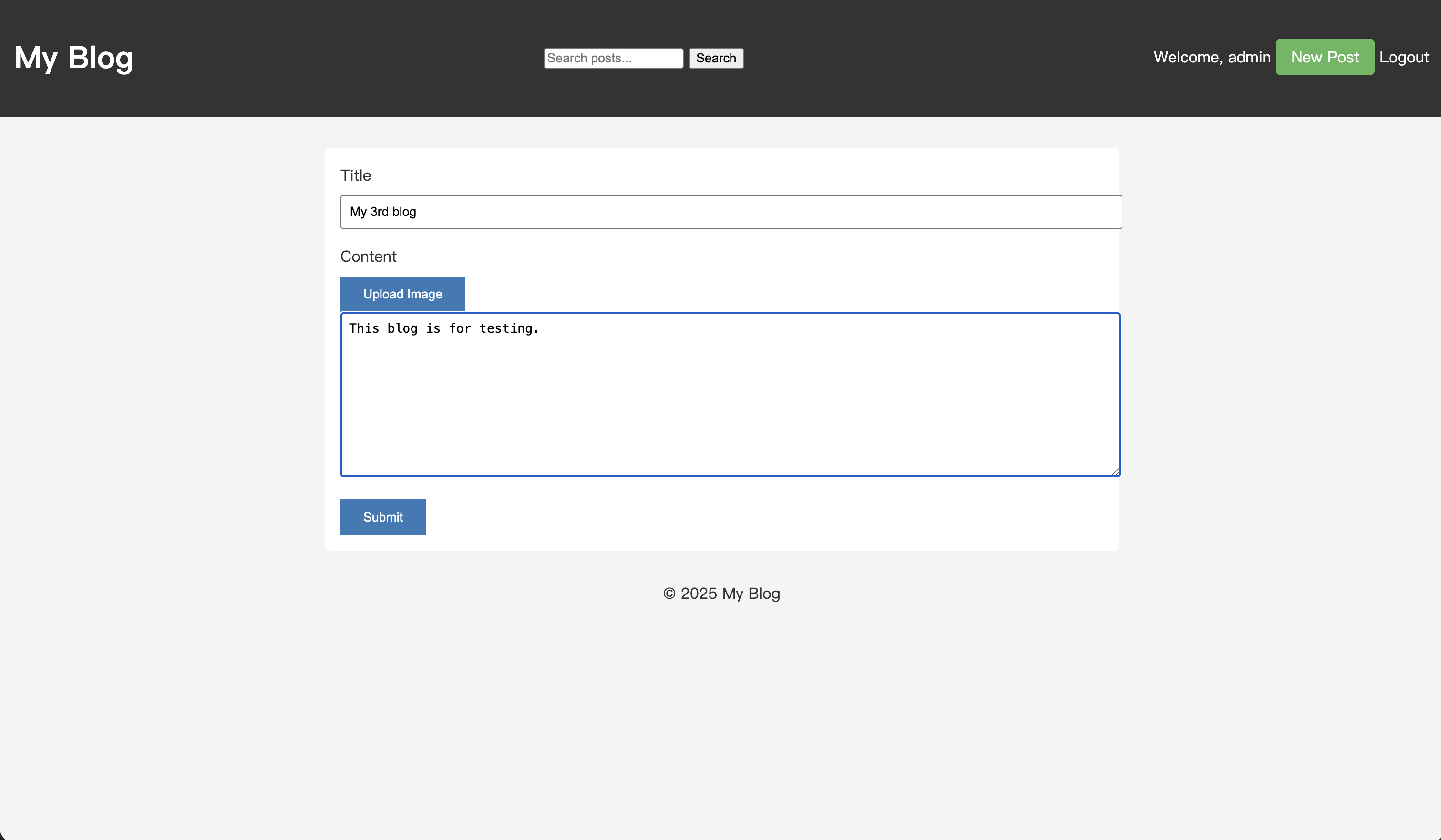
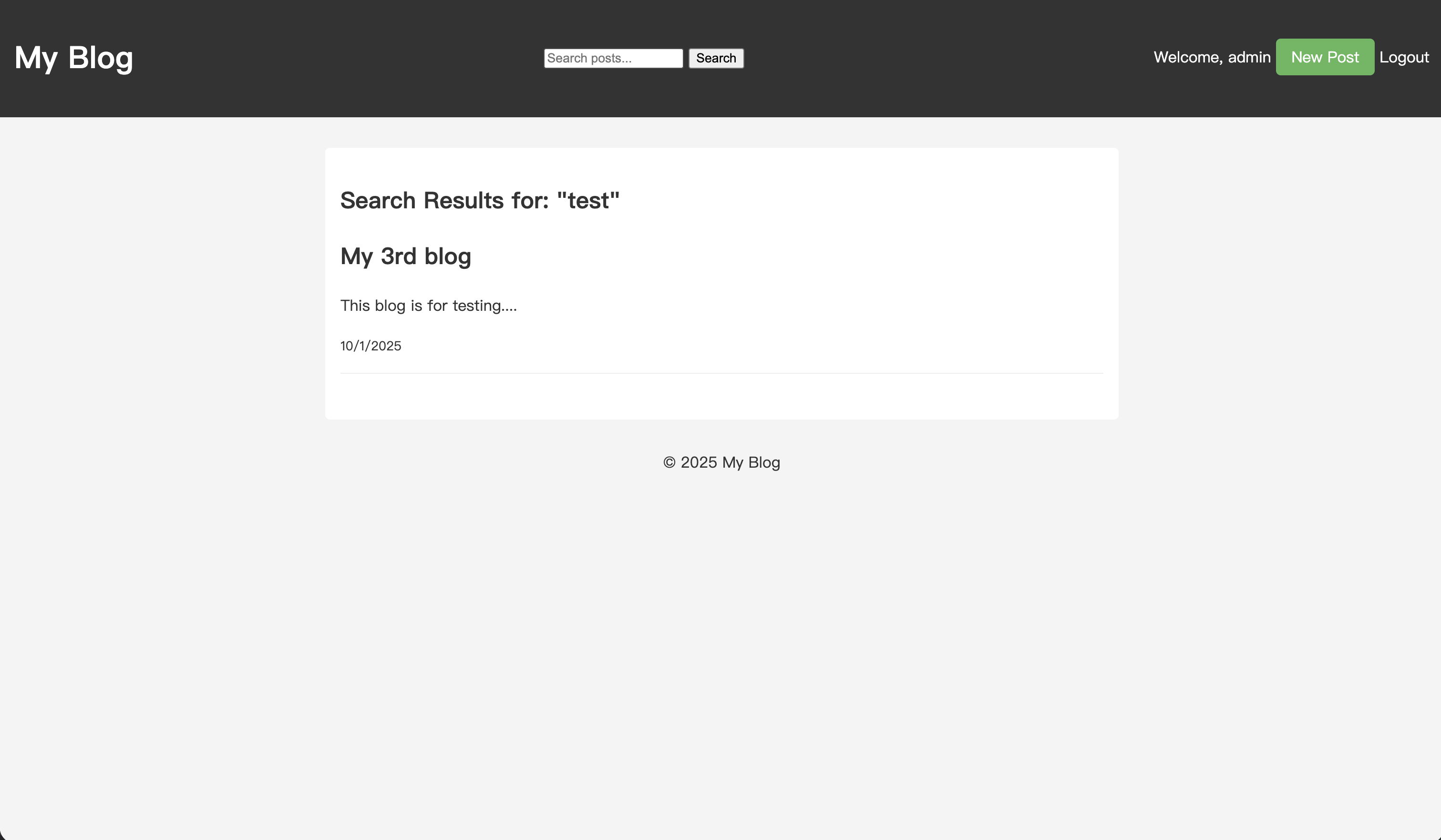
投稿を保存した後、検索ボックスに「test」と入力して検索を実行します。
検索結果ページで、作成したばかりの記事が結果に表示されます。
これで、ブログは全文検索機能をサポートするようになりました。どれだけ書いても、読者が迷うことはもうありません。